What is ASLR and when should it be used
ASLR, or Address Space Layout Randomization, is a technique used to prevent or limit the effectiveness of exploits involving memory corruption. This loads the executable and libraries for a given process at random locations in memory, making their placement difficult to guess. Many types of attacks require an adversary to know or guess the location of code, and if locations are guessed incorrectly a process may crash instead of executing code desired by the adversary.
This post focuses on the impact of compiling binaries so that ASLR can be enabled. However, prior to that I’ll discuss when one would want to use enable ASLR compared to other security techniques.
When an adversary attacks a system he must accomplish two tasks: first he must subvert the program’s flow from its expected course, and second he must cause the program to behave in the manner he desires. In a traditional buffer overflow attack which overwrite the stack, an attacker will complete the first task by overwriting a return address on the stack. This will cause the program to jump to another location when it returns from some function. The second task is accomplished by injecting instructions, or shellcode, somewhere into memory. By jumping to the injected code an attacker can change the behavior of a program.
To defend against the attacker’s first task, some compiler toolchains provide support for a shadow stack, where return addresses are maintained elsewhere in memory away from the program stack. This provides a defense against or prevents attacks which require overwriting the stack to change return addresses. However, the overhead for a shadow stack can be between 3.5~10% or more [source, source] which may not be practical for some products.
As for the attacker’s second task, an easy location to store shellcode is on the stack itself. Preventing stacks from being executable is the first line of defense for such an attack. Other locations in memory can also be overwritten, such as places where code already exists. If a system supports the NX bit feature then areas with code can be marked executable but not writable, which will further thwart such attacks.
The first steps to hardening a program should be to prevent an attacker from injecting his own instructions and executing them. This, however, does not prevent all possible attacks. Instead, if an attacker cannot inject his own instructions, he can instead use code which already exists. This code must be somewhere in memory, and to use it the attacker must be able to find it.
There are several types of attacks which are possible that leverage existing code. Examples include Jump Oriented Programming [source], Return-into-libc [source], and Return Oriented Programming [source]. In each of these, an attacker needs to locate existing code in memory to further an attack.
ASLR provides probabilistic protection against these attacks by loading the executable and libraries into memory at random locations, thus making them more difficult to locate. By default when an application is compiled the the location where libraries appear in memory will be fixed. An executable cannot simply enable ASLR, however, as the application itself must know how to find the libraries and functions inside of those libraries during execution.
To allow ASLR, an application, which includes the executable as well as used libraries, needs to be compiled with an option to allow the resulting code to be position independent. This is called PIE, or Position Independent Executable. When compiled as a PIE (at least for GCC) a register is dedicated to hold the base address for the current module. By reducing the number of registers available some code will experience register pressure, thus resulting in code being less efficient when executed and taking longer to complete [source)]. For architectures with few registers, such as x86 (8 registers), a loss of a register may be significant. However, architectures with more registers, such as x86_64 and ARM (both with 16) the impact may be smaller.
The remaining of this article will focus in the performance impact of PIE executables on an x86 machine.
Analyzing position independent compiled executables
To analyze the impact of compiling executables to be position independent, two metrics relevant to an embedded system will be used:
- Increased code size
- Performance cost
In addition, a discussion about memory usage will be presented, although no experiments will be run.
To facilitate the analysis, a custom Linux distribution was built using Yocto, one build with PIE enabled for all executables/libraries which support it and one build without PIE enabled. The build was run on QEMU and analyzed. See this post on how to create a custom QEMU image, in my case on macOS.
The Yocto build was a bare-bones build with one exception: FFmpeg was included which will be used to compare performance. Adding FFmpeg was accomplished by adding the following to the conf/local.conf file in the build directory:
# Add ffmpeg and allow its commercial license flag
CORE_IMAGE_EXTRA_INSTALL += "ffmpeg"
LICENSE_FLAGS_WHITELIST += "commercial"
# Add extra space (in KB) to the file system, so that the
# benchmark has space to output its file(s).
IMAGE_ROOTFS_EXTRA_SPACE = "512000"To enable PIE the following was added to the conf/local.conf file:
# Include the following file:
# poky/meta/conf/distro/include/security_flags.inc
# which enables all packages to build with additional
# security flags. Some packages cannot be built with
# some flags, so blacklist those.
require conf/distro/include/security_flags.inc
# Only build with PIE support and ignore all other security flags.
SECURITY_CFLAGS = "-pie -fpie"
SECURITY_NO_PIE_CFLAGS = ""
SECURITY_LDFLAGS = ""
SECURITY_X_LDFLAGS = ""Code size
The Yocto builds were configured to produce a EXT4 file system image. Following are the number of KB used on the file systems:
| Build | Size (KB) |
|---|---|
| No Flags | 34,844 |
| PIE | 34,892 |
This shows that compiling with PIE support does result in an additional 48 KB of storage, which is an increase of ~0.1%.
Performance cost
As mentioned earlier, compiling with PIE support results in dedicating a register to hold the base address of the current module. By dedicating this register there are fewer registers available to do relevant work, and as a result there may be some performance cost if that register could have been used for something else. However, the question is can the performance cost be measured or is it exceedingly small?
To quantify the performance impact, an experiment was conducted which encoded a small video 20 times in succession using FFmpeg, once with and once without PIE enabled. See this post for details on the experiment and the video file which was used.
The following two box plots show the results of the experiment (raw data here).
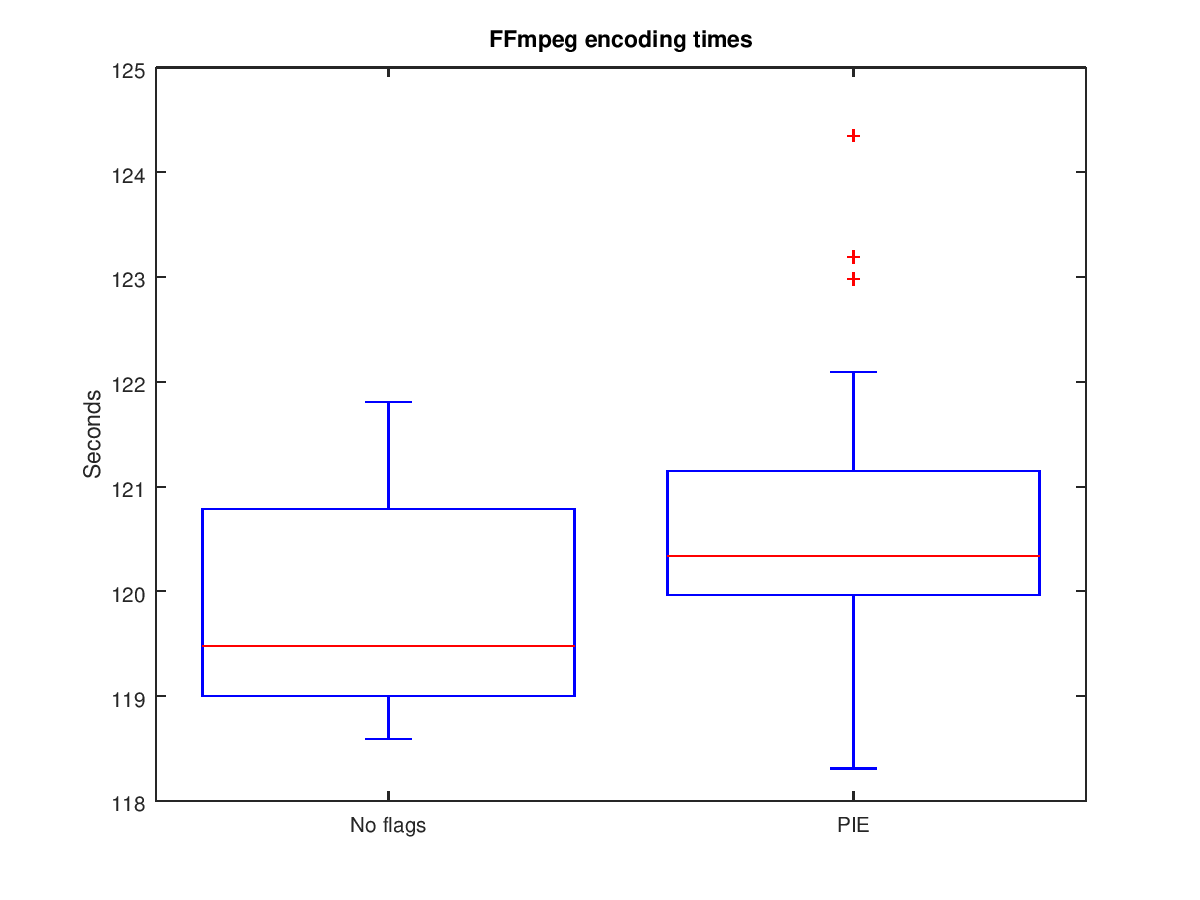
The results show that in this experiment compiling binaries to support ASLR results in an average processing time increase of 0.86 seconds, 0.7%. This increase, although measurable, is relatively small, especially compared to some of the other techniques available for thwarting buffer overflow attacks (such as a shadow stack, which could decrease performance by 3.5~10%). Note though that there is a study which is more comprehensive and shows there may be other workloads that have higher performance impacts when enabling PIE on x86 [source].
Memory implications
In addition to having a performance hit in terms of processing times, there is also a memory implication with enabling ASLR. One technique used to save memory on an embedded system is to prelink executables at compile time. Prelinking performs some relocation decisions offline. As a result, when the dynamic linker is invoked to start a program fewer relocations are made which reduces startup time and, more importantly, reduces run-time memory consumption.
Compiling executables to support position independences does not prevent them from also being prelinked. However, enabling ASLR on prelinked executables does override the decisions made offline. This does result in losing all of the run-time memory savings of prelinking.
If the memory savings of prelinking are important for a system, it may be worth compiling only select executables with PIE. A starting point for determining which executables may be at a higher risk for exploitation are the requirements provided by the Fedora Linux distribution. Namely, for that distribution, compiling with PIE (and thus enabling ASLR) is required if the package:
- runs as root
- has setuid binaries, or
- is long running, e.g. once started is likely to keep running until a reboot.
In addition, PIE is suggested but not required if a package:
- accepts or processes untrusted input.
Conclusion
ASLR is one technique available to reduce the possibility that an attacker will successfully exploit a given buffer overflow or other memory corruption vulnerability. There are other techniques which should probably be pursued first to make memory corruption attacks harder to exploit. However, ASLR is effective and should be pursued if other areas have been hardened and the system can tuck the potential performance loss and the additional memory usage (if prelinking is use elsewhere) can be tolerated.