Writing bug-free software is hard
Writing “good” software, for whatever definition of good you pick, is not easy. It can be even more difficult to write software which is secure. There are a number of techniques available for helping one develop software which has few or no security vulnerabilities. Examples include creating an architecture informed by potential threats to secure development practices. No technique is perfect, but when combined together the expectation is that the resulting product should have fewer vulnerabilities, and those that exist should have reduced impact if found.
Nothing is free, and each technique includes trade-offs. The trade-offs many relate to an increased development effort or increased cost to a product. For an embedded system, where devices may have reduced memory or CPU horsepower, that cost may be reduced performance.
Unless a system is trivial, it contains bugs. Writing software without bugs is hard, and proving that there are no bugs is even harder. As security is an emergent property in a system, demonstrating that a system is free of vulnerabilities is a difficult problem. One interesting technique for either reducing the impact of vulnerabilities or stopping them from being exploitable is to “harden” a program by instrumenting the resulting binaries to check for issues at runtime. These issues can be buffer overflows, out-of-bounds object accesses, etc.
Recently I was in a position where I needed to propose and defend the addition of “hardening” options to a networked embedded product. The goal was to help find existing and new defects in-house and protect customers from being vulnerable to exploits from yet undiscovered defects. One of the hurdles was determining the performance implication of the different hardening options.
This post, as well as several future posts, will each tackle a single topic on hardening a product. As well as providing details on the topic, some performance metrics will be presented. The expectation is that the analysis should give some context to if the protection a hardening option provides is worth the performance trade-off.
Stack smashing protection
This post’s topic is Stack Smashing Protection (SSP). SSP is a technique where a compiler will instrument a binary to check if part of the program stack has been overwritten. A canary is placed before the return address on the stack. Before returning from a function the canary is verified. If the value of the canary matches the original value, the function returns. Otherwise, something changed the value of the canary (which could be a buffer overflow, and out of bounds write, etc) and the program is terminated. As a result, a potential exploit is reduced to a denial-of-service.
First, how does SSP work? I’ll speak to GCC’s implementation of SSP; other compiler’s implementation are likely not too different.
When a program first loads, a stack canary is determined which will be used for the rest of the program’s run. GCC’s implementation in libssp can be found here. On Linux, the canary is read from /dev/urandom; if the read value is ‘0’ an alternative value is used.
void *__stack_chk_guard = 0;
static void __attribute__ ((constructor)) __guard_setup (void)
{
unsigned char *p;
if (__stack_chk_guard != 0)
return;
int fd = open ("/dev/urandom", O_RDONLY);
if (fd != -1)
{
ssize_t size = read (fd, &__stack_chk_guard, sizeof (__stack_chk_guard));
close (fd);
if (size == sizeof(__stack_chk_guard) && __stack_chk_guard != 0)
return;
}
/* If a random generator can't be used, the protector switches the guard
to the "terminator canary". */
p = (unsigned char *) &__stack_chk_guard;
p[sizeof(__stack_chk_guard)-1] = 255;
p[sizeof(__stack_chk_guard)-2] = '\n';
p[0] = 0;
}During execution if a function is instrumented it will write the canary on entry and check it before returning. If the canary does not match, the program is terminated. Following is an example of how the instrumented code may look [source]:
extern uintptr_t __stack_chk_guard;
noreturn void __stack_chk_fail(void);
void foo(const char* str)
{
uintptr_t canary = __stack_chk_guard;
char buffer[16];
strcpy(buffer, str);
if (canary != __stack_chk_guard)
__stack_chk_fail();
}Terminating the program is not straight forward, unfortunately, as the state of the program is not known when a failure is detected. For example, raising a signal may not work, as signals may be blocked. When terminating a program, libssp will make multiple attempts to stop the program.
static void fail (const char *msg1, size_t msg1len, const char *msg3)
{
/*
* Message is written to the tty or syslog, code omitted.
*/
/* Try very hard to exit. Note that signals may be blocked preventing
the first two options from working. The use of volatile is here to
prevent optimizers from "knowing" that __builtin_trap is called first,
and that it doesn't return, and so "obviously" the rest of the code
is dead. */
{
volatile int state;
for (state = 0; ; state++)
switch (state)
{
case 0:
/*
* Cause the program to exit abnormally using a target-dependent
* mechanism. May call abort() or execute an illegal instruction.
*/
__builtin_trap ();
break;
case 1:
/*
* Dereference an address which is both not mapped into the
* process and is unaligned.
*/
*(volatile int *)-1L = 0;
break;
case 2:
/*
* Terminate this process "immediately". Any open file
* descriptors are, closed, child processes are inherited
* by pid 1, and this process' parent is sent a SIGCHLD.
* Any functions registered with atexit(3) or on_exit(3)
* are not called.
*/
_exit (127);
break;
}
}
}
void __stack_chk_fail (void)
{
const char *msg = "*** stack smashing detected ***: ";
fail (msg, strlen (msg), "stack smashing detected: terminated");
}Not all functions need be instrumented. GCC provides three options [details here]:
-fstack-protector:
Functions with vulnerable objects, which include buffers larger than 8 bytes
or calls to alloca, are instrumented.
-fstack-protector-strong:
In addition to the functions instrumented by -fstack-protector, this flag also
instruments functions with local arrays or references to local frame addresses.
-fstack-protector-all:
Every function is instrumented.
Instrumenting all functions is known to result in a significant performance hit [source]. -fstack-protector and -fstack-protector-strong attempt to mitigate this by instrumenting only a subset of functions. Traditional stack overflows are the result of string-based manipulations, and -fstack-protector is intended to cover many of these cases. However, there are rare cases where stack overflows are caused by other types of stack variables. -fstack-protector-strong is intended to cover more of these cases [source].
Analyzing stack smashing protection
As -fstack-protector-strong strikes a balance between security and performance, this version of SSP is analyzed. Two metrics relevant to an embedded system will be used for the analysis:
- Increased code size
- Performance cost
To facilitate the analysis, a custom Linux distribution was built using Yocto, one build with SSP enabled and one without. The build was run on QEMU and analyzed. See this post on how to create a custom QEMU image, in my case on macOS.
The Yocto build was a bare-bones build with one exception: FFmpeg was included which will be used to compare performance. Adding FFmpeg was accomplished by adding the following to the conf/local.conf file in the build directory:
# Add ffmpeg and allow its commercial license flag
CORE_IMAGE_EXTRA_INSTALL += "ffmpeg"
LICENSE_FLAGS_WHITELIST += "commercial"
# Add extra space (in KB) to the file system, so that the
# benchmark has space to output its file(s).
IMAGE_ROOTFS_EXTRA_SPACE = "512000"To enable SSP the following was added to the conf/local.conf file:
# Include the following file:
# poky/meta/conf/distro/include/security_flags.inc
# which enables all packages to build with additional
# security flags. Some packages cannot be built with
# some flags, so blacklist those.
require conf/distro/include/security_flags.inc
# Only build with SSP and ignore all other security flags.
SECURITY_CFLAGS = "-fstack-protector-strong"
SECURITY_NO_PIE_CFLAGS = "-fstack-protector-strong"
SECURITY_LDFLAGS = "-fstack-protector-strong"
SECURITY_X_LDFLAGS = "-fstack-protector-strong"Code size
The Yocto builds were configured to produce a EXT4 file system image. Following are the number of KB used on the file systems:
| Build | Size (KB) |
|---|---|
| No Flags | 34,844 |
| SSP | 35,056 |
This shows that SSP code instrumentation adds an additional 212 KB (~0.25MB) of storage, which is an increase of ~0.6%. Your mileage may vary, as the increase depends on the type of code being compiled.
Performance cost
Adding the additional instructions will result in some performance cost, as the additional instruction do take a non-zero amount of time to execute. However, the question is can the performance cost be measured or is it exceedingly small?
To quantify the performance impact, an experiment was conducted which encoded a small video using FFmpeg. This experiment was selected because video encoding is a non-trivial process and should have a variety of types of code involved for encoding, which should provide a use case representative to code used in real systems. In addition, using FFmpeg itself is a good example to show the relevance of security, as there have been security vulnerabilities identified in the past which could be exploited to execute arbitrary code. (Examples: CVE-2016-10190, CVE-2016-10191, CVE-2016-10192)
The FFmpeg experiment consists of re-encoding a x264 video file in a flv container to a mp4 container as well as re-encoding its aac audio track. The video file is the 640x360 1MB flv file from samples-videos.com: big_buck_bunny_360p_1mb.flv [alternate link]. The FFmpeg command line to perform the conversion is:
$ ffmpeg -y -i big_buck_bunny_360p_1mb.flv -c:v libx264 -c:a aac out.mp4The experiment took place in QEMU running on a 2015 Macbook Pro, where QEMU was given 1 CPU and 1GB of RAM. The video file was re-encoded 20 times for each build and the processing times were recorded. The laptop was otherwise idle during the trials to reduce noise in the data. The following two box plots show the results of the experiment (raw data here).
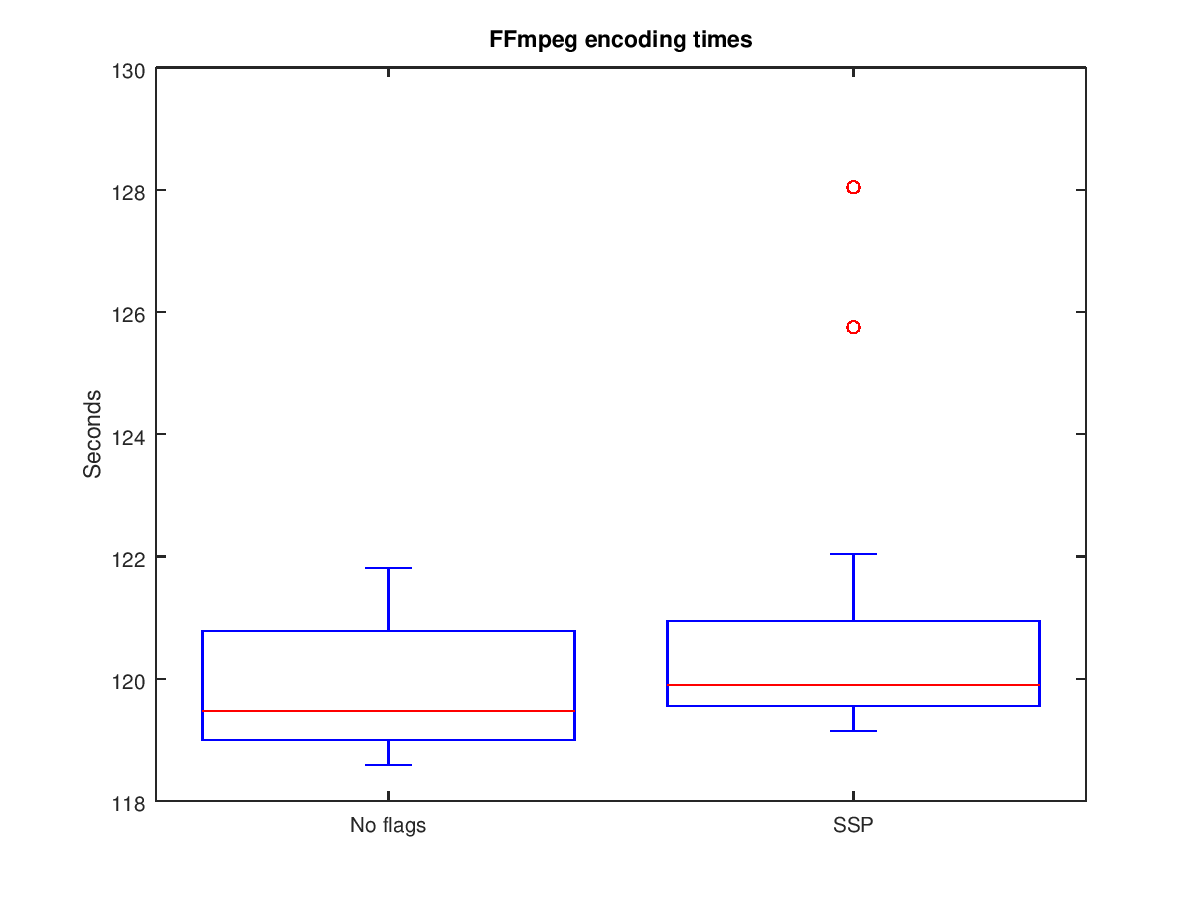
The results show that there may be a performance impact when enabling SSP, however if it exists it is modest. The median values of the two plots are very close, which indicates that both builds can produce encoding times which are similar. Although the first and third quartile of the SSP build are slightly skewed, note that there are also two outliers. These outliers are the first two encoding attempts for the SSP trial. As the experiments are run on QEMU, there may be affects on the host system that are difficult to isolate, such as something processing on the host to which I was not aware. If these two outliers are removed, the results show much closer encoding times:
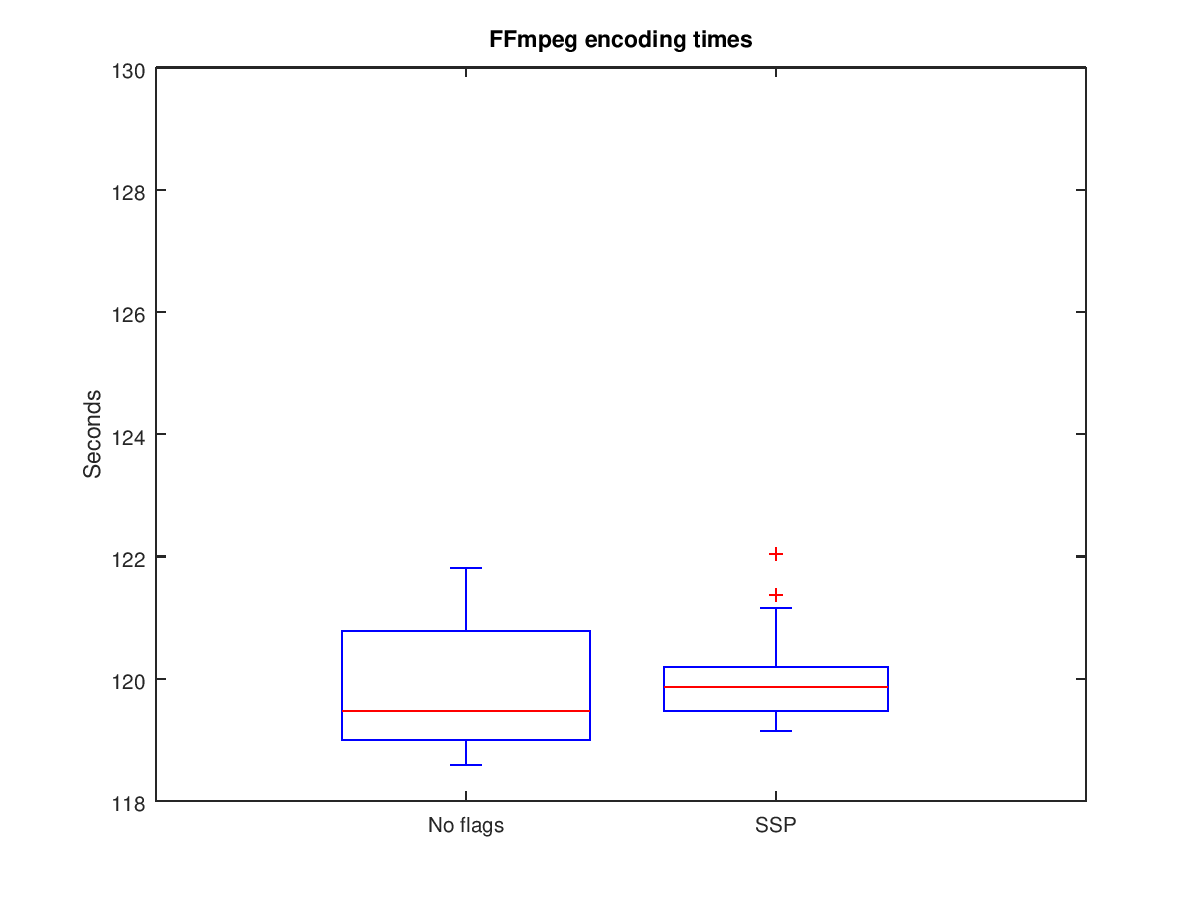
Conclusion
Stack Smashing Protection does provide some protection against latent buffer overflow defects which could be exploitable. Enabling it on a system may slightly increase the storage size of the executables (0.6% in this case). There may be a performance hit, however, it is modest at best. If the extra code storage cost is feasible, it may be worth enabling SSP if there is risk that the system could process data from the outside world which could be used to trigger an exploit.