Linux kernel and vulnerabilities
The number of devices running Linux each day is astounding. Android alone consists of 2 billion devices as of 2017. Some devices which run Linux receive regular updates, however many receive infrequent updates if any. Kernel bugs themselves tend to be long lived, with critical and high bugs remaining undetected for 5-6 years on average. There will always be bugs, and they will continue to exist whether we are aware of them or not. To this end, preventing bugs from being exploitable is of upmost importance.
A number of options have been added to the Linux kernel to validate that various types of memory corruptions have not occurred. One example is Stack Smashing Protection, mentioned in this post. This post focuses on other options which are more narrowly focused. These are discussed below. Note that the discussion is limited to Kernel v4.8; there may be changes in later versions which improve or change the options.
Linked List Sanity Checks
The CONFIG_DEBUG_LIST option, when used, will enable additional validation on linked list structures in the Kernel. An example of an exploit which leverages the corrupting of linked lists is (CVE-2017-10661)[https://access.redhat.com/security/cve/CVE-2017-10661], which uses a race condition and simultaneous operations to corrupt a list. This is fixed here, for the curious.
The option was added in this commit, and results in sanity checks being added to linked list operations:
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (unlikely(next->prev != prev)) {
printk(KERN_ERR "list_add corruption. next->prev should be %p, but was %p\n",
prev, next->prev);
BUG();
}
if (unlikely(prev->next != next)) {
printk(KERN_ERR "list_add corruption. prev->next should be %p, but was %p\n",
next, prev->next);
BUG();
}
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty on entry does not return true after this, the entry is
* in an undefined state.
*/
void list_del(struct list_head *entry)
{
if (unlikely(entry->prev->next != entry)) {
printk(KERN_ERR "list_del corruption. prev->next should be %p, but was %p\n",
entry, entry->prev->next);
BUG();
}
if (unlikely(entry->next->prev != entry)) {
printk(KERN_ERR "list_del corruption. next->prev should be %p, but was %p\n",
entry, entry->next->prev);
BUG();
}
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}Credential Sanity Checks
The CONFIG_DEBUG_CREDENTIALS option was added here and adds sanity checks to credentials. This adds the following to a credential structure:
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
...as well as adding the following validations:
static inline bool creds_are_invalid(const struct cred *cred)
{
if (cred->magic != CRED_MAGIC)
return true;
if (atomic_read(&cred->usage) < atomic_read(&cred->subscribers))
return true;
#ifdef CONFIG_SECURITY_SELINUX
if ((unsigned long) cred->security < PAGE_SIZE)
return true;
if ((*(u32*)cred->security & 0xffffff00) ==
(POISON_FREE << 24 | POISON_FREE << 16 | POISON_FREE << 8))
return true;
#endif
return false;
}Notifiers Sanity Checks
Validation of notifier chains was added here to check that notifiers are from the kernel or a still-loaded module prior to being invoked. This is enabled with the CONFIG_DEBUG_NOTIFIERS option. The check is fairly light weight, and is as follows:
if (!kernel_text_address((unsigned long)n->notifier_call)) {
WARN(1, "Invalid notifier registered!");
return 0;
}Scatter/Gather Table Sanity Checks
Scatter/Gather tables are a mechanism used for high performance I/O on DMA devices. Details on this can be found in this article. Sanity checks to scatter/gather tables was added to the Kernel here and can be enabled with the CONFIG_DEBUG_SG option. This adds an extra entry to scatter/gather tables, as shown below:
struct scatterlist {
#ifdef CONFIG_DEBUG_SG
unsigned long sg_magic;
#endifadd also adds sanity checks when modifying or inspecting entries, such as:
#define SG_MAGIC 0x87654321
struct scatterlist *sg_next(struct scatterlist *sg)
{
#ifdef CONFIG_DEBUG_SG
BUG_ON(sg->sg_magic != SG_MAGIC);
#endif
...
}Stack End Sanity Checks
The CONFIG_SCHED_STACK_END_CHECK option was added here to check in schedule() if a stack has been overrun. If it is, BUG() is invoked results in executing an undefined instruction, thus causing the current running process to die. Enabling this option adds the following sanity check to ensure the end of the stack is not corrupted:
#define task_stack_end_corrupted(task) \
(*(end_of_stack(task)) != STACK_END_MAGIC)
/*
* Various schedule()-time debugging checks and statistics:
*/
static inline void schedule_debug(struct task_struct *prev)
{
#ifdef CONFIG_SCHED_STACK_END_CHECK
if (task_stack_end_corrupted(prev))
panic("corrupted stack end detected inside scheduler\n");
#endif
...
}An example of a bug which this catches can be found here, which is a vulnerability that allows one to recurse arbitrarily until the stack is overrun.
Analyzing stack smashing protection
To determine the performance implications of the aforementioned configurations, a custom Linux distribution was built using Yocto, one build with the configurations enabled in the kernel and one without. Linux v4.8 was used in the comparison. Two metrics relevant to an embedded system will be used for the analysis:
- Increased code size
- Performance cost
The build was run on QEMU and analyzed. See this post on how to create a custom QEMU image, in my case on macOS.
The Yocto build was a bare-bones build with one exception: FFmpeg was included which will be used to compare performance. Adding FFmpeg was accomplished by adding the following to the conf/local.conf file in the build directory:
# Add ffmpeg and allow its commercial license flag
CORE_IMAGE_EXTRA_INSTALL += "ffmpeg"
LICENSE_FLAGS_WHITELIST += "commercial"
# Add extra space (in KB) to the file system, so that the
# benchmark has space to output its file(s).
IMAGE_ROOTFS_EXTRA_SPACE = "512000"To enable SSP the following kernel configuration was added:
CONFIG_DEBUG_KERNEL=y
CONFIG_SCHED_STACK_END_CHECK=y
CONFIG_DEBUG_LIST=y
CONFIG_DEBUG_SG=y
CONFIG_DEBUG_NOTIFIERS=y
CONFIG_DEBUG_CREDENTIALS=yCode size
The kernel images being compared are the bzImage files created by Yocto. Following are the sizes in KB of the kernel images from the two builds:
| Build | Size (KB) |
|---|---|
| No Flags | 6,881 |
| Sanitizers | 6,890 |
This shows that adding the sanitizers does add an additional 9 KB. This is rather small, and an increase of 0.1%.
Performance cost
The validation of the mentioned kernel instructions does results in additional instructions being executed, and is expected to incur some performance penalty. However, the question is can the performance cost be measured or is it exceedingly small?
To quantify the performance impact, an experiment was conducted which encoded a small video 20 times in succession using FFmpeg, once with and once without the kernel debug configurations mentioned earlier. See this post for details on the experiment and the video file which was used.
The following two box plots show the results of the experiment (raw data here).
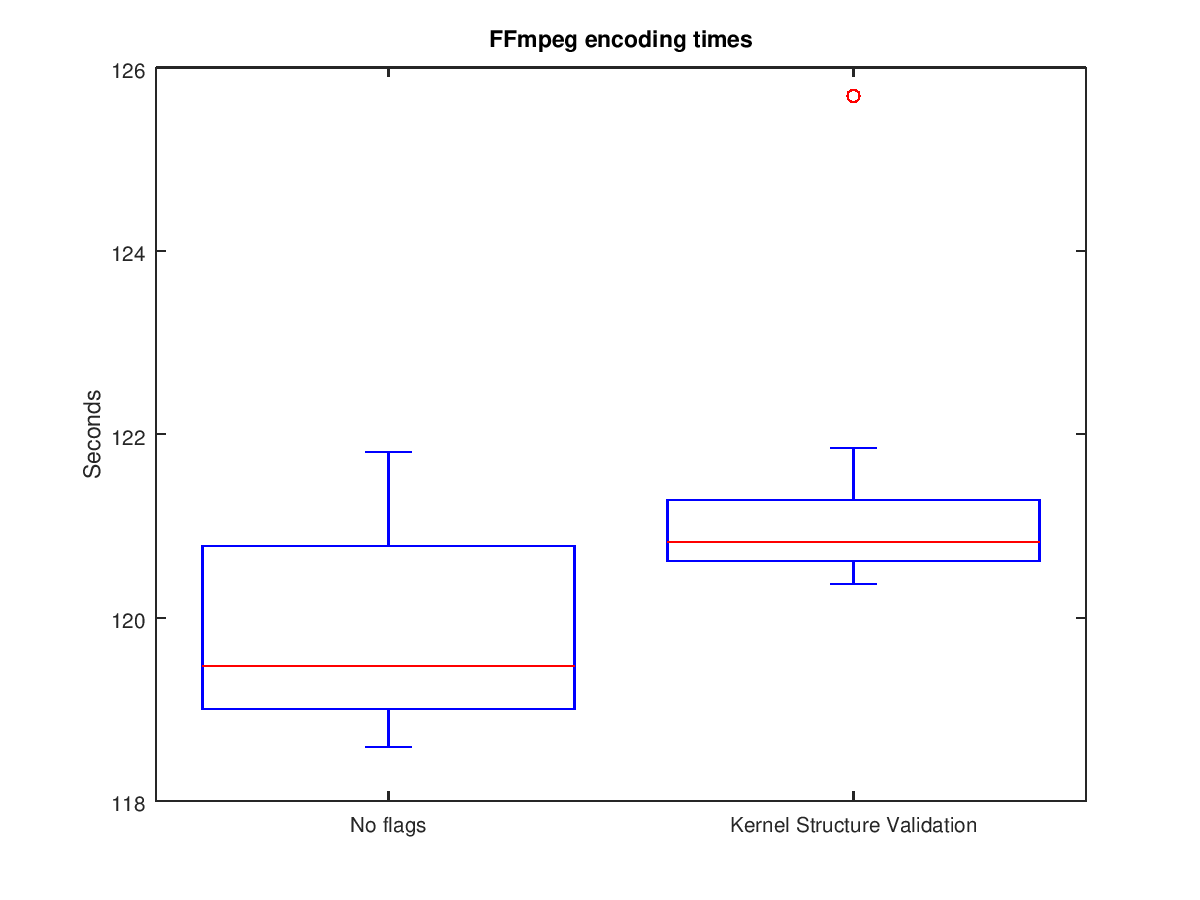
The results show that there is some performance cost, as they increase encoding time on an average of 1.3 seconds. This is a performance hit of 1.1%.
Conclusion
The validation checks do provide some protection against vulnerabilities resulting from corruptions in various kernel data structures. The code size increase is rather small, which is intuitive given the limited code which is used to perform the validations. The runtime overhead of the checks, however, is not small. For the CPU bound work load of encoding videos with ffmpeg an increase of 1.1% was observed.
There are several options available to harden a Linux system. If one has a given performance loss budget that must be adhered to, consider the trade-off of the options presented with these kernel configurations with other opportunities. It depends on one’s threat landscape, but there may be larger impact hardening options for a similar or reduced performance hit.